March 21, 2026 · 4 min read
Governance by Markdown
A developer's AI playbook went viral this week. Every rule in it points at a governance problem. The markdown file just isn't where governance lives.
By AmplefAI
A Claude Code playbook made the rounds this week.
A markdown file full of rules for how an AI coding agent should behave: plan before executing, verify before marking done, log mistakes, don't ship without proof, reuse skills, treat the file system as context.
The engagement made sense. Developers were bookmarking it, forking it, adapting it for their own setups. And fair enough. The instincts are right.
Plan the work. Check the work. Learn from failure. Don't cut corners.
Any senior engineer would say the same.
The problem is not the rules.
The problem is where the rules live.
Rules Without Teeth
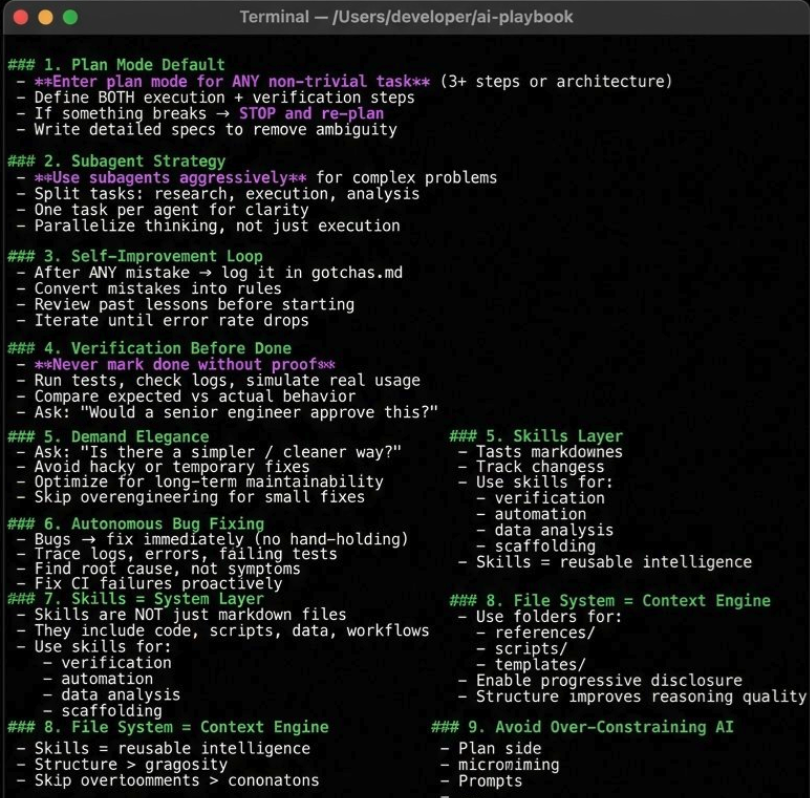
The problem is not the quality of the rules. It's that they live in a markdown file and depend on model compliance.
That playbook is a markdown file injected into a prompt.
The agent reads it and then, hopefully, follows it.
Hopefully is doing a lot of work there.
There is no proof the agent planned before acting. No proof it verified before marking something done. No evidence showing which skill was invoked, what context it operated on, or whether the output matched the intent. No durable record that a past mistake informed the next run.
The developer wrote a constitution.
But there is no court, no enforcement, and no evidence locker.
That is governance by suggestion.
And it works right up until it matters.
The Single-Agent Illusion
To be clear, this setup is completely reasonable at small scale.
One developer. One agent. One repo. One terminal.
The human is the governance layer.
They review the output, inspect the diff, catch the hallucination, rerun the test, correct the course. The playbook helps make the agent more predictable, which makes the human loop easier.
Most serious developers working with coding agents are doing some version of this.
But that is a workflow, not infrastructure.
And workflows do not survive the jump from one person managing one agent to multiple agents operating across repos, runtimes, and clouds.
At that point, a markdown file in a prompt is not governance. It is a prayer.
What Breaks at Scale
Take that same setup and spread it across a team.
Now ask a few boring but important questions.
Did the agent actually verify before marking the task done?
What context did it have when it made the decision?
What policy was in force at that moment?
Did another agent learn from the failure, or just repeat it somewhere else?
Can you prove, not claim, that every action stayed within policy last Tuesday?
You can't.
Because there is no ledger. No signed authorization. No forensic chain from intent to context to decision to outcome.
There is a markdown file and an LLM you hope complied.
That gap is everywhere right now.
Every "best practices" repo. Every agent playbook. Every prompt-engineering guide that has quietly started reinventing governance in natural language.
The instinct is right. The enforcement surface is wrong.
Where This Goes
This is the part the market is starting to see.
Agents need rules, yes.
But once the agent matters operationally, rules in prompts are not enough.
If a rule matters, it cannot live as a suggestion to the model.
It has to live outside the model.
It has to be evaluated before action, recorded at decision time, and provable after the fact.
That is the difference between guidance and governance.
And that is also the difference between a useful local workflow and infrastructure you can actually trust.
From Prompted Behavior to Governed Execution
This is the problem space we built AmplefAI for.
Not to write better instructions for agents, but to make execution governable.
So "plan before acting" becomes authorized dispatch. "verify before done" becomes structured write-back against original intent. "learn from mistakes" becomes durable institutional memory with provenance. And every meaningful action becomes traceable, replayable, and enforceable.
Same instinct.
Different substrate.
Governance Is Not a Prompt
The playbook was directionally right, which is why it resonated.
But governance does not live in markdown. It does not live in a system prompt. And it definitely does not live in hope.
A markdown file can remind an agent what good behavior looks like. It cannot prove that behavior happened.
That gap — between rules you can write and rules you can enforce — is where the next layer of AI infrastructure gets built.
AmplefAI builds the independent governance layer that ensures AI capability remains accountable to your institution — not your provider.
Learn more at amplefai.comAmplefAI
Continue Reading
Follow the thinking
We're building the constitutional layer for autonomous AI — in public. Get new posts delivered.
No spam. Governance-grade email only.